
实时警报通知:微信告警通知的重要性解析
1675
2023-01-22
本文讲述了安全告警数据分析之道:数据透视篇(一),告警分析系统
日前,在企业安全运营当中,SIEM的热潮已经逐渐淡去,很多企业已经逐渐成立了安全运营中心(SOC),收集到了海量安全数据。但是如何利用这些数据,如何进行分析等问题并没有很好地解决。数据往往只是做简单存储,数据价值未得到体现。
其实在网络安全领域最重要的还是“数据”,做攻击离不开各种资产数据、漏洞数据,做防御离不开资产数据、设备告警数据,对各种攻击活动的分析更是离不开DNS、样本、用户行为等数据,《安全告警数据分析之道》为系列文章,旨在对企业网络侧安全告警数据进行深入分析,挖掘数据的潜在价值,助力企业日常安全运营。
实际上为了分析安全告警,近年来一些公司以数据分析、人工智能的方法来分析这些数据,而分析、理解数据,进而对数据进行标记往往是使用人工智能算法等高级算法的必备条件,但这一前置过程往往被忽略。
本文为系列文章的首篇,浅谈对安全告警数据分析的思考,并且以一次实际网络攻防演习数据为例,介绍对告警数据进行标记的方法,分析并总结可能的研究点和数据的潜在价值。
随着现代企业网络结构的复杂化,如复杂的网络分区、企业上云、新型网络设备等,安全设备的告警量与日剧增。虽然SOC团队一般会对这些告警数据进行存储,但是暴增的数据量与合理分析方法的缺失进一步加重了SOC团队的压力。根据实际经验,一般来说,一个业务稍微复杂一点的大中型企业,每天的告警数据量会达到百万量级。
在工业界,这类数据基本组成少有暴露,数据的整体轮廓往往不得而知,而处理方法往往太过抽象,如使用UEBA的方法,目前笔者也尚未接触到对此类数据进行完整分析的方法;另一方面,在学术领域,对IDS的数据研究从本世纪初就开始了,然而那时候的网络结构比较简单、攻击手法较为单一,近些年虽然也有零星的研究成果出现,但依然使用20年前的数据集,借鉴意义不大。那么安全告警分析之路该何去何从?安全告警数据到底有何价值?本文将给出见解。
如图1所示,企业一般会在内网和企业网络出口部署安全设备,这些安全设备会对流经的网络流量进行威胁分析。而主流的安全设备的检测方式还是基于规则的检测,并且对于加密流量并没有什么好方法,最多也就是能记录一些加密通信的日志,如SSL协商日志。总结来说基于网络侧的安全告警数据分析无法解决以下问题:
1、 不经过安全设备的流量。实际上这种场景很常见,企业往往只会在重要资产前或者大的区域前部署安全设备,而且攻击者也有各种各样的方式让流量不经过安全设备;
2、 不在规则中的攻击行为。大型网络演习中,攻击者往往会掏出珍藏的0-day漏洞进行攻击,这种攻击不会在网络侧产生告警,往往需要在主机上做进一步的检测;
3、 加密流量。基于DPI的安全设备无法解密加密流量,只能设法(如,拿到目标网站的证书)解密后再处理。
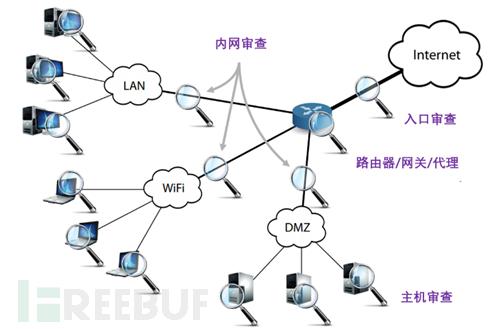
图1 安全设备部署方式
为了分析海量安全告警数据,以比较成熟的安全运营人员为例,他们往往会采取如下方式进行数据处理:
1、 只关注重要资产。特定目标的告警量往往不多,可以进行分析;
2、 只关注特定类型的告警。有经验的运营人员知道特定安全产品的置信度比较高的告警,他们往往只会关注置信度比较高、危害较大的告警类型。
虽然这种方式能够对告警做一个粗略的排序,挑选出高威胁的告警进行分析,但是显然这种方法是不完善的,且不说有时候需要进行多个告警的联合分析,不得不关注其余告警,就算是只关注特定的告警,还是有大量的攻击行为在剩余告警中,不能弃之不顾。
那么分析安全告警能分析出什么来呢?我们知道,不仅是攻击流量,正常流量也会被安全设备看到,所谓的“高误报率”就是由这部分流量导致的,这部分流量同样可以被利用起来,用于做资产梳理,梳理内网环境,具体来说,安全告警分析能做到:
1、 资产梳理。我们知道大型企业资产往往很混乱,人工很难梳理清楚,这在日常安全运营中也是一大痛点。但是实际上,通过告警数据可以对IP做部分资产梳理工作,不同类型的资产对应的告警差异性往往较大,可以进行分析归类;
2、 灰色行为识别。以漏洞扫描为例,例行的漏洞扫描是正常操作,而没有报备的扫描行为则是异常操作,对这种灰色行为的跟踪也是发现攻击的有效途径;
3、 攻击行为识别。安全设备的初衷。
本小节将对一次网络攻防演习数据做简单分析,分析这些数据的组成以及可能的处置方法,阐述数据价值。
本文收集了某中型企业的一次网络攻防演习(共计5天)的网络侧安全告警数据,基本的数据统计信息如图2所示,可以看到在这5天之内,每天收集到的告警数据多达上千万条,五天总计5000多万条告警。其中,认证类、目录遍历类和文件传输类的告警为数量占比前三的告警类型,三者之和可占总告警量的70%以上。除了少量的真实攻击,绝大部分的告警都是无害的,让我们抽丝剥茧,看看这些“奇葩”数据的真面目!
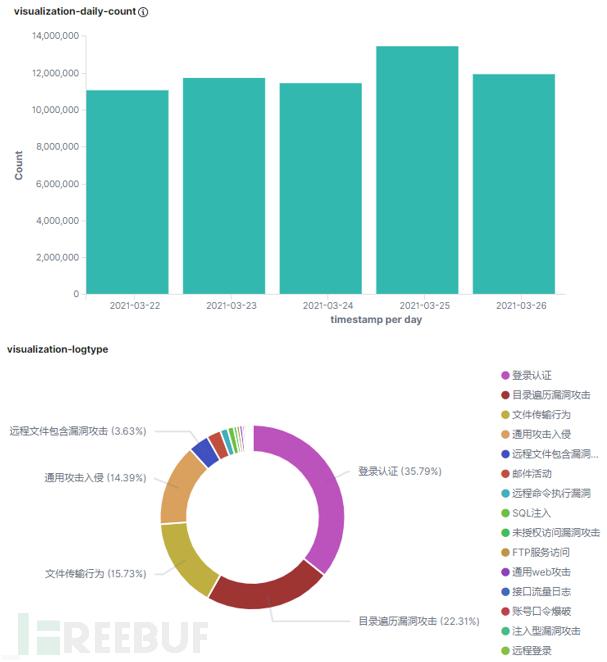
图2 安全告警数据数量和类型统计
1)提取有用字段
由于原始数据包含很多无用信息,我们需要对数据的可用字段做一定的筛选,最终,对于每条告警我们挑选出如下9个有用字段:
timestamp:告警产生时间
sip:源IP
dip:目的IP
device_ip: 产生此条告警的探针IP
dport:目的端口
log_message:告警类型
payload:告警载荷(IP层以上数据)
q_body:Web访问的请求体
r_body:Web请求的响应体
其中,若告警是由Web请求触发的,则有q_body字段,否则只有payload字段,另外,可能会因为设备原因导致部分字段不完整。
特别说明,几乎所有的对IDS告警分析的学术文章都不会将payload等数据包载荷信息纳入分析范围,而在日常运营中这部分信息也是判断攻击的重要依据,不能舍弃。故保留payload、q_body字段,而r_body是判断攻击是否成功的重要依据,同样需要考虑;另一方面,由于不同探针产生的攻击告警(如外网、内网)的分布会呈现一定差异,为了区分,device_ip字段同样需要保留。
2)数据去重
我们知道一个数据包从企业外部到内部的传输过程中,往往会经过多个检测设备,这样就会产生重复告警,这部分的告警应该删除。理想情况下,同一时刻,同一攻击者对同一目标的攻击行为应该只有一条告警。为了达到这个目标我们依据(timestamp,sip,dip,dport ,payload)对原始告警进行去重。当然这样也有例外情况,如:报文延时过大,timestamp不一致,设备问题,对于不同的payload截断后payload相同等等,不过这些情况基本可以忽略。
3)数据分析
一般来说,除去某些特别不准的告警类型之外,log_message字段可以比较准确地反映出当前数据包的攻击类型。我们对告警类型做了分布分析,如图3左图所示,横坐标为log_message编号,纵坐标为该告警类型发生的次数,可以看到告警类型体现出明显的长尾分布特性,如图3右图所示。我们按照幂律分布的统计方法,横坐标为告警发生次数的对数,纵坐标为这类告警的数量,以图中红框标记的点(0,58)为例,说明在整个数据集中,只有1条记录的告警类型有58种。这类数据分布上的分析,有助于后续高级算法模型的选择。
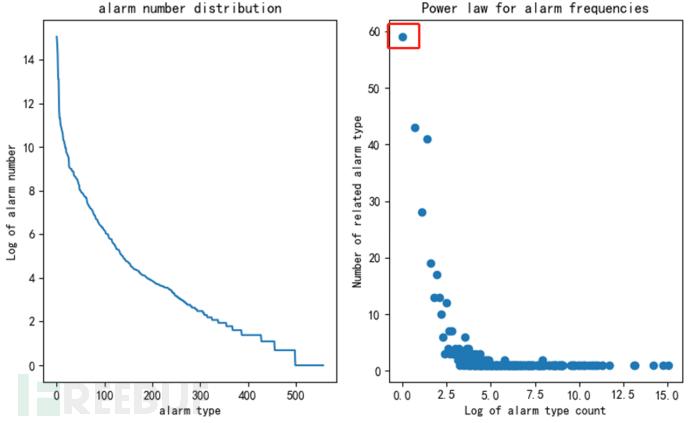
图3 以告警类型为角度的统计分布图
通过以上数据,我们可以看到,从告警类型(log_message)的维度,告警呈现出明显的长尾分布特性。其实不光是告警类型这一属性,在源IP、目的IP等多个属性上,如图4,图5所示,分别以sip、dip为维度进行统计,横纵坐标的含义与图3类似,告警分布均展现出了类似的特性。
在多种维度上,告警均展现出明显长尾分布特性,这一特性不仅可以为选择高级算法模型(如word2vec算法)提供有效信息,还很直观地告诉我们:告警分布具有一定的规律性!而告警的这种规律性和流量的自相似性是分不开的,对于这种现象的成因我们在本文不做深入讨论,我们仅需要利用这种特性帮我们进行下一步告警分析:由于攻击流量或者说异常流量本身占比极小,告警的这种规律性是长期存在的,过滤这些占绝大多数的规律性的告警,剩下的就是重要度较高的告警了。
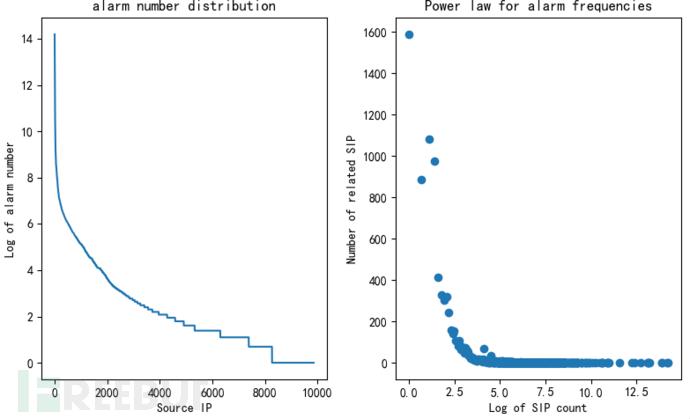
图4 以源IP为角度的统计分布图
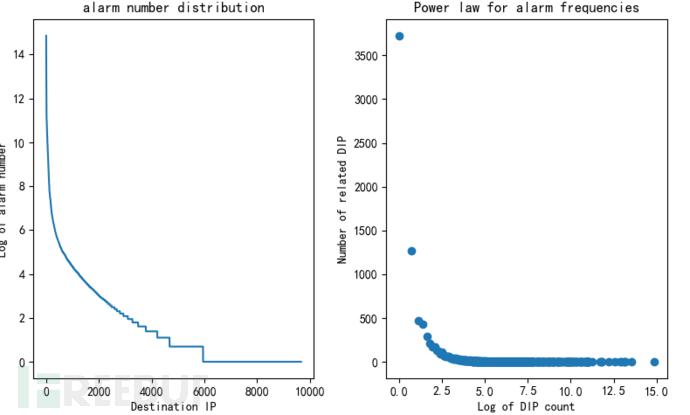
图5 以目的IP为角度的统计分布图
4)数据分类
整体上我们可以按照:数量大到数量小,重要程度低到重要程度高的原则对告警进行过滤、分类,尽量首先将数量大、重要度低的正常告警过滤掉,我们以数据集中触发告警量最多的源IP:10.5.237.232为例,如图6左图所示,该IP与大量目的IP均有告警产生.图6右图表明,触发告警类型最多的是代理连接,并且呈现明显的规律性,对外网的代理连接在一般处理过程中重要度较低,因此10.5.237.232在此期间内触发的“HTTP协议CONNECT隧道功能(http proxy)连接访问”类型的告警分类为正常告警(正常业务导致),这一条过滤规则即可过滤600多万条告警,约13%的告警量。
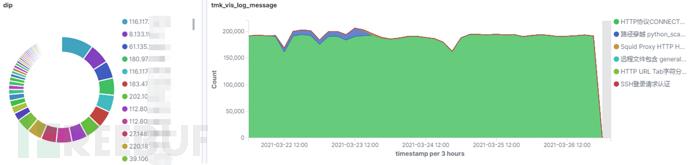
图6 正常告警示例(10.5.237.232触发)
需要特别注意的是,我们需要以一种较细的粒度来对告警进行分类,即结合多种维度对告警进行分类筛选,举个例子:IP地址A经常性的触发告警,我们不能就直接忽略A所触发的告警,而应该关注其具体的内容,什么类型的告警是常见的,什么类型的告警是不常见的。
更具体的,如图7上半部分所示,10.66.240.216整体上触发的告警数量比较均匀,乍看没有异常.下半部分表明,10.66.240.216在短时间内对10.245.38.183发起了大量的扫描,而这种扫描行为是突发的、不常规的,对于企业内网来说,存在较大隐患,但是由于其隐藏于源IP触发的大量告警之中,在上半部分的图中很难被发现。
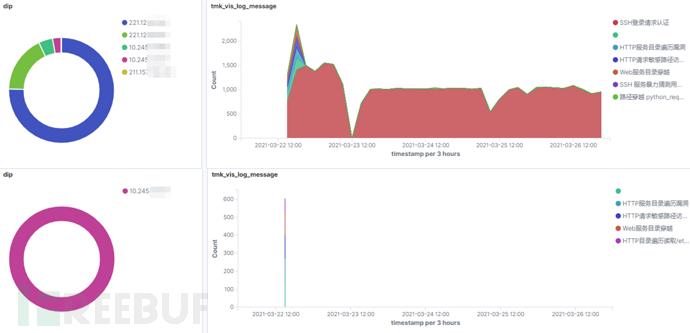
图7 异常告警示例(10.66.240.216触发)
总结来说,我们需要以数量大到数量小,重要程度低到重要程度高的原则找出大部分正常告警,在执行过程中,以一种较细的粒度进行归并统计(如,[sip,dip]的双重维度)。
5)分析结果
通过自动化结合人工的方法,我们得以对大部分的告警做出分析结果,并打上标签。总结来说,告警数据可以分为4大类:
1. 正常告警。该部分由正常行为组成,通常都是由正常业务导致,包含正常的漏洞扫描任务等;
2. 低危告警。互联网上存在大量的蠕虫、僵尸网络,这些肉鸡会进行大量常态化的攻击行为,这些攻击往往都不会成功,可以认定为低危告警,做IP封禁操作;
3. 灰色行为。该部分告警展现出一定的威胁性,需要做出一定的处置,如:未报备的内网扫描行为、内网蠕虫传播行为等等,需要联系相应的资产负责人做进一步核查;
4. 高危告警。正在发生或者已经发生的入侵行为。
这4类告警数据量依次递减,重要程度依次增加。
本文从宏观上讨论了告警分析所能带来的价值,以一次真实的网络攻防演习数据为例,在对数据简单统计分析的基础上,探讨了对这类数据进行分类分析的大致方向,并对数据进行了简单的归类。本文为系列文章的首篇,讨论进行安全告警数据分析的整体方向,接下来的文章将进一步介绍我们对数据打标签的具体算法,敬请期待。
在本文中,我们将探讨如何设计一个可扩展的指标监控和告警系统。 一个好的监控和告警系统,对基础设施的可观察性,高可用性,可靠性方面发挥着关键作用。
下图显示了市面上一些流行的指标监控和告警服务。

接下来,我们会设计一个类似的服务,可以供大公司内部使用。
从一个小明去面试的故事开始。

面试官:如果让你设计一个指标监控和告警系统,你会怎么做?
小明:好的,这个系统是为公司内部使用的,还是设计像 Datadog 这种 SaaS 服务?
面试官:很好的问题,目前这个系统只是公司内部使用。
小明:我们想收集哪些指标信息?
面试官:包括操作系统的指标信息,中间件的指标,以及运行的应用服务的 qps 这些指标。
小明:我们用这个系统监控的基础设施的规模是多大的?
面试官:1亿日活跃用户,1000个服务器池,每个池 100 台机器。
小明:指标数据要保存多长时间呢?
面试官:我们想保留一年。
小明:好吧,为了较长时间的存储,可以降低指标数据的分辨率吗?
面试官:很好的问题,对于最新的数据,会保存 7 天,7天之后可以降低到1分钟的分辨率,而到 30 天之后,可以按照 1 小时的分辨率做进一步的汇总。
小明:支持的告警渠道有哪些?
面试官:邮件,电 钉钉,企业微信,Http Endpoint。
小明:我们需要收集日志吗?还有是否需要支持分布式系统的链路追踪?
面试官:目前专注于指标,其他的暂时不考虑。
小明:好的,大概都了解了。
总结一下,被监控的基础设施是大规模的,以及需要支持各种维度的指标。另外,整体的系统也有较高的要求,要考虑到可扩展性,低延迟,可靠性和灵活性。
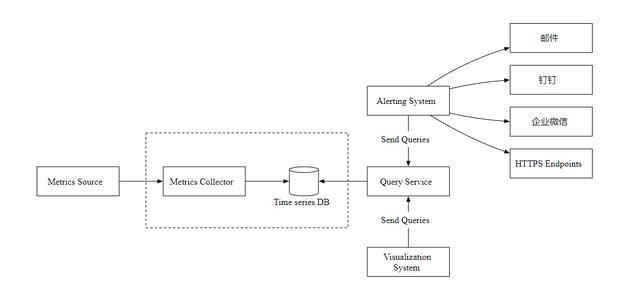
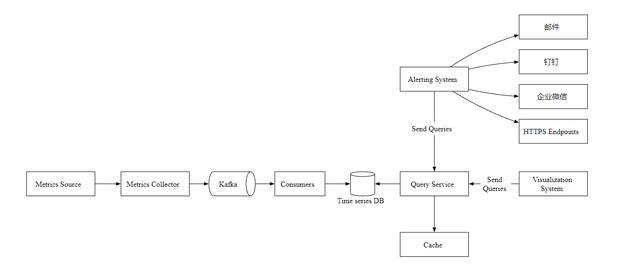
一个指标监控和告警系统通常包含五个组件,如下图所示
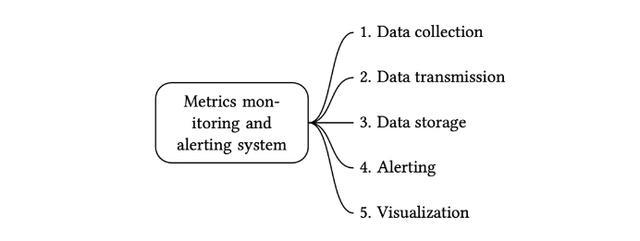
数据收集:从不同的数据源收集指标数据。
数据传输:把指标数据发送到指标监控系统。
数据存储:存储指标数据。
告警:分析接收到的数据,检测到异常时可以发出告警通知。
可视化:可视化页面,以图形,图表的形式呈现数据。
指标数据通常会保存为一个时间序列,其中包含一组值及其相关的时间戳。
序列本身可以通过名称进行唯一标识,也可以通过一组标签进行标识。
让我们看两个例子。
示例1:生产服务器 i631 在 20:00 的 CPU 负载是多少?
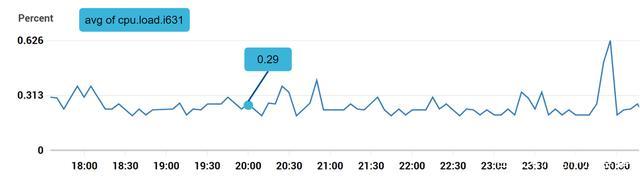
上图标记的数据点可以用下面的格式表示
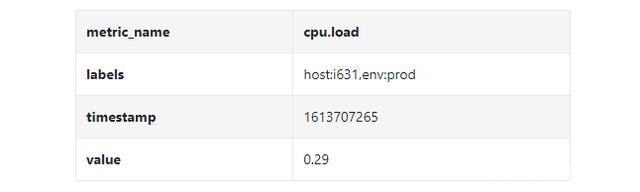
在上面的示例中,时间序列由指标名称,标签(host:i631,env:prod),时间戳以及对应的值构成。
示例2:过去 10 分钟内上海地区所有 Web 服务器的平均 CPU 负载是多少?
从概念上来讲,我们会查询出和下面类似的内容
CPU.load host=webserver01,region=shanghai 1613707265 50CPU.load host=webserver01,region=shanghai 1613707270 62CPU.load host=webserver02,region=shanghai 1613707275 43
我们可以通过上面每行末尾的值计算平均 CPU 负载,上面的数据格式也称为行协议。是市面上很多监控软件比较常用的输入格式,Prometheus 和 OpenTSDB 就是两个例子。
每个时间序列都包含以下内容:
指标名称,字符串类型的 metric name 。
一个键值对的数组,表示指标的标签,List<key,value>
一个包含时间戳和对应值的的数组,List <value, timestamp>
数据存储是设计的核心部分,不建议构建自己的存储系统,也不建议使用常规的存储系统(比如 MySQL)来完成这项工作。
理论下,常规数据库可以支持时间序列数据, 但是需要数据库专家级别的调优后,才能满足数据量比较大的场景需求。
具体点说,关系型数据库没有对时间序列数据进行优化,有以下几点原因
在滚动时间窗口中计算平均值,需要编写复杂且难以阅读的 SQL。
为了支持标签(tag/label)数据,我们需要给每个标签加一个索引。
相比之下,关系型数据库在持续的高并发写入操作时表现不佳。
那 NoSQL 怎么样呢?理论上,市面上的少数 NoSQL 数据库可以有效地处理时间序列数据。比如 Cassandra 和 Bigtable 都可以。但是,想要满足高效存储和查询数据的需求,以及构建可扩展的系统,需要深入了解每个 NoSQL 的内部工作原理。
相比之下,专门对时间序列数据优化的时序数据库,更适合这种场景。
OpenTSDB 是一个分布式时序数据库,但由于它基于 Hadoop 和 HBase,运行 Hadoop/HBase 集群也会带来复杂性。Twitter 使用了 MetricsDB 时序数据库存储指标数据,而亚马逊提供了 Timestream 时序数据库服务。
根据 DB-engines 的报告,两个最流行的时序数据库是 InfluxDB 和 Prometheus ,它们可以存储大量时序数据,并支持快速地对这些数据进行实时分析。
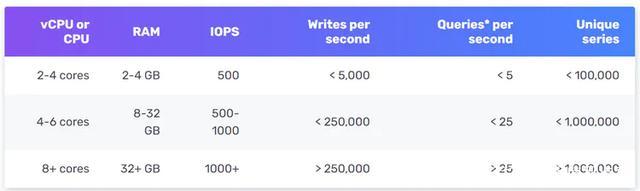
如下图所示,8 核 CPU 和 32 GB RAM 的 InfluxDB 每秒可以处理超过 250,000 次写入。
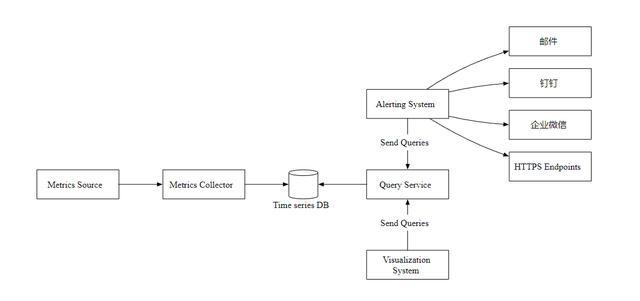
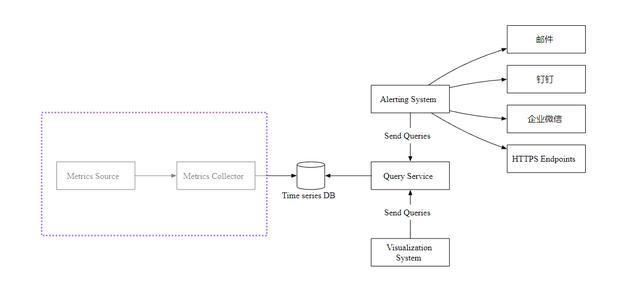
Metrics Source 指标来源,应用服务,数据库,消息队列等。
Metrics Collector 指标收集器。
Time series DB 时序数据库,存储指标数据。
Query Service 查询服务,向外提供指标查询接口。
Alerting System 告警系统,检测到异常时,发送告警通知。
Visualization System 可视化,以图表的形式展示指标。
现在,让我们聚焦于数据收集流程。主要有推和拉两种方式。
拉模式
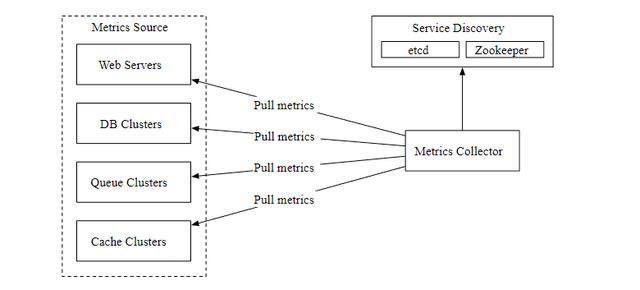
上图显示了使用了拉模式的数据收集,单独设置了数据收集器,定期从运行的应用中拉取指标数据。
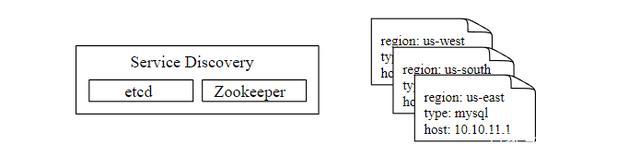
这里有一个问题,数据收集器如何知道每个数据源的地址? 一个比较好的方案是引入服务注册发现组件,比如 etcd,ZooKeeper,如下
下图展示了我们现在的数据拉取流程。
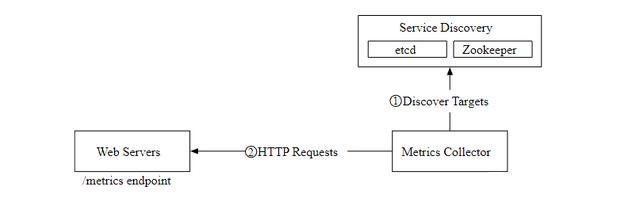
指标收集器从服务发现组件中获取元数据,包括拉取间隔,IP 地址,超时,重试参数等。
指标收集器通过设定的 HTTP 端点获取指标数据。
在数据量比较大的场景下,单个指标收集器是独木难支的,我们必须使用一组指标收集器。但是多个收集器和多个数据源之间应该如何协调,才能正常工作不发生冲突呢?
一致性哈希很适合这种场景,我们可以把数据源映射到哈希环上,如下
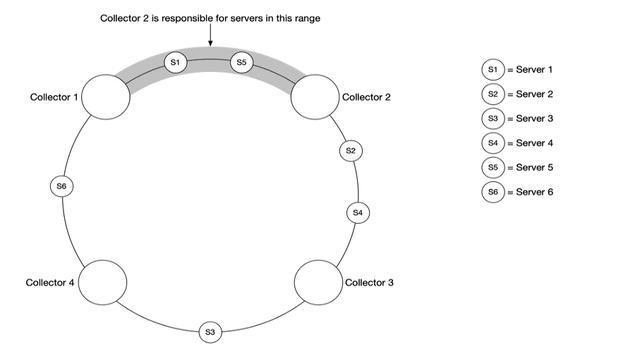
这样可以保证每个指标收集器都有对应的数据源,相互工作且不会发生冲突。
推模式
如下图所示,在推模式中,各种指标数据源(Web 应用,数据库,消息队列)直接发送到指标收集器。
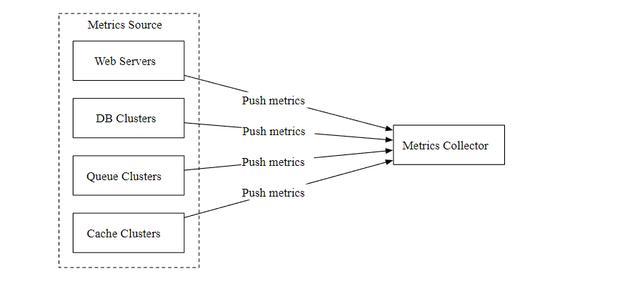
在推模式中,需要在每个被监控的服务器上安装收集器代理,它可以收集服务器的指标数据,然后定期的发送给指标收集器。
推和拉两种模式哪种更好?没有固定的答案,这两个方案都是可行的,甚至在一些复杂场景中,需要同时支持推和拉。
现在,让我们主要关注指标收集器和时序数据库。不管使用推还是拉模式,在需要接收大量数据的场景下,指标收集器通常是一个服务集群。
但是,当时序数据库不可用时,就会存在数据丢失的风险,所以,我们引入了 Kafka 消息队列组件, 如下图
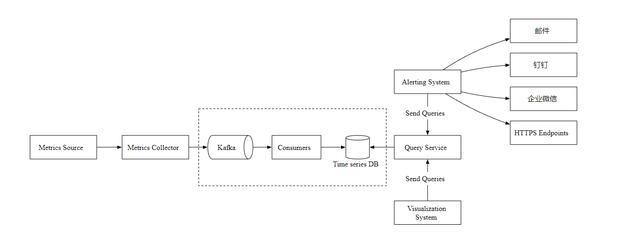
指标收集器把指标数据发送到 Kafka 消息队列,然后消费者或者流处理服务进行数据处理,比如 Apache Storm、Flink 和 Spark, 最后再推送到时序数据库。
指标在多个地方都可以聚合计算,看看它们都有什么不一样。
客户端代理:客户端安装的收集代理只支持简单的聚合逻辑。
传输管道:在数据写入时序数据库之前,我们可以用 Flink 流处理服务进行聚合计算,然后只写入汇总后的数据,这样写入量会大大减少。但是由于我们没有存储原始数据,所以丢失了数据精度。
查询端:我们可以在查询端对原始数据进行实时聚合查询,但是这样方式查询效率不太高。
大多数流行的指标监控系统,比如 Prometheus 和 InfluxDB 都不使用 SQL,而是有自己的查询语言。一个主要原因是很难通过 SQL 来查询时序数据, 并且难以阅读,比如下面的SQL 你能看出来在查询什么数据吗?
select id, temp, avg(temp) over (partition by group_nr order by time_read) as rolling_avgfrom ( select id, temp, time_read, interval_group, id - row_number() over (partition by interval_group order by time_read) as group_nr from ( select id, time_read, "epoch"::timestamp + "900 seconds"::interval * (extract(epoch from time_read)::int4 / 900) as interval_group, temp from readings ) t1) t2order by time_read;
相比之下, InfluxDB 使用的针对于时序数据的 Flux 查询语言会更简单更好理解,如下
from(db:"telegraf") |> range(start:-1h) |> filter(fn: (r) => r._measurement == "foo") |> exponentialMovingAverage(size:-10s)
数据编码和压缩可以很大程度上减小数据的大小,特别是在时序数据库中,下面是一个简单的例子。
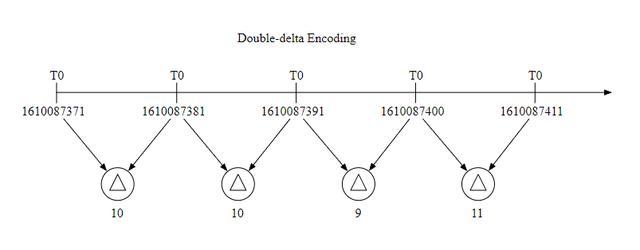
因为一般数据收集的时间间隔是固定的,所以我们可以把一个基础值和增量一起存储,比如 1610087371, 10, 10, 9, 11 这样,可以占用更少的空间。
下采样是把高分辨率的数据转换为低分辨率的过程,这样可以减少磁盘使用。由于我们的数据保留期是1年,我们可以对旧数据进行下采样,这是一个例子:
7天数据,不进行采样。
30天数据,下采样到1分钟的分辨率
1年数据,下采样到1小时的分辨率。
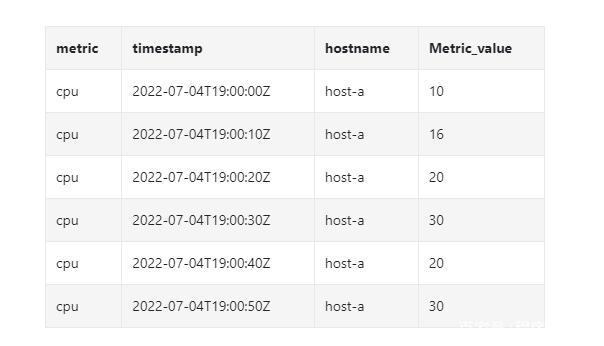
我们看另外一个具体的例子,它把 10 秒分辨率的数据聚合为 30 秒分辨率。
原始数据
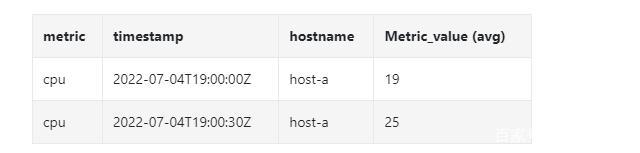
下采样之后
让我们看看告警服务的设计图,以及工作流程。
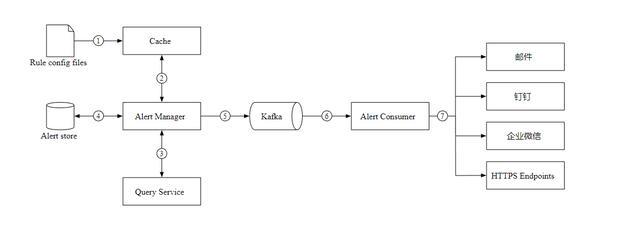
加载 YAML 格式的告警配置文件到缓存。
- name: instance_down rules: # 服务不可用时间超过 5 分钟触发告警. - alert: instance_down expr: up == 0 for: 5m labels: severity: page
警报管理器从缓存中读取配置。
根据告警规则,按照设定的时间和条件查询指标,如果超过阈值,则触发告警。
Alert Store 保存着所有告警的状态(挂起,触发,已解决)。
符合条件的告警会添加到 Kafka 中。
消费队列,根据告警规则,发送警报信息到不同的通知渠道。
可视化建立在数据层之上,指标数据可以在指标仪表板上显示,告警信息可以在告警仪表板上显示。下图显示了一些指标,服务器的请求数量、内存/CPU 利用率、页面加载时间、流量和登录信息。

Grafana 可以是一个非常好的可视化系统,我们可以直接拿来使用。
在本文中,我们介绍了指标监控和告警系统的设计。在高层次上,我们讨论了数据收集、时序数据库、告警和可视化,下图是我们最终的设计:
上文就是小编为大家整理的安全告警数据分析之道:数据透视篇(一),告警分析系统。
国内(北京、上海、广州、深圳、成都、重庆、杭州、西安、武汉、苏州、郑州、南京、天津、长沙、东莞、宁波、佛山、合肥、青岛)睿象云智能运维平台软件分析、比较及推荐。


发表评论
暂时没有评论,来抢沙发吧~