
实时警报通知:微信告警通知的重要性解析
932
2023-01-22
本文讲述了告警查询及处理的优化之路,告警处理流程包括。
最近一直在折腾告警查询优化的问题,我们场景:用户希望查询其所负责设备的最近10条告警消息。我们系统存在两端访问:一个是PC端,另一个是小程序端。其中,PC端并发少些,小程序端并发要求比较高,需要达到500+TPS。由于设备量比较多,我们预估一个月的告警数据量在1000万+。另外,用户可以对告警数据进行处理操作。如何在兼顾大数据量的秒级查询及高并发的范围查询,我们做了一些探索和尝试。
PC端我们是通过ClickHouse的ReplacingMergeTree引擎来实现告警查询及处理的。具体的实现过程,可参考我的这篇文章:基于ReplacingMergeTree来实现告警处理。由于ClickHouse的并发性能不行,在我们8C 16G虚拟机上,1000万数据ClickHouse的查询并发在10以下,与500相差甚远。优缺点整理如下:
优点:
1、以新增替代更新(告警处理),性能高,吞吐量大。
2、查询性能高,千万告警数据,分页查询平均响应秒级。
缺点:并发查询能力不足。
针对ClickHouse并发问题,我们也做了相关的优化:一方面,考虑到告警处理的业务场景并发不高,操作不频繁。告警处理的时候,可以一并触发表Merge过程,通过OPTIMIZE TABLE yourtablename FINAL。这样告警查询的时候少了聚合操作,性能有3倍左右的提升。另一方面:还是要提升SQL执行的整体性能,经过第一阶段的优化,在8C 16G的VM上,300万左右的告警数据,单次查询响应时长在:300-500毫秒左右,TPS在10左右。我们可以适当的增加CPU或者换个好点的磁盘,或者干脆直接换物理机器,来提升查询的总体TPS,目测100+还是很容易达到的。
在有限的资源下,如何提升查询并发数?我们是ClickHouse的重度使用者,既然ClickHouse做不到,那么哪个中间件可以呢?分析下我们的业务场景有两个特性是ClickHouse不擅长做的:更新和高并发。我们想到了Redis。
zset 是 Redis 提供的最具特色的数据类型之一,首先它是一个 set,这保证了内部 value 值的唯一性,其次它给每个 value 添加了一个 score(分值)属性,通过对分值的排序实现了有序化。我们想通过ZSET来实现高并发查询,遇到了如下难题:
1、小程序端查询的筛选条件很多可以自由组合
2、用户能看到其所属组织下所有设备的告警信息
一条告警上报的时候,我们会在告警接收模块进行告警的维度信息补齐,比如:告警设备所属组织树path。ClickHouse中是通过在告警表里面增加组织树path字段,查询的时候通过组织树的path进行模糊匹配来实现的。那么在Redis,我们打算以告警设备所属的组织树path为key,分数为告警时间,value为告警的内容。形如如下的操作:
zadd 00-AH-a7tyhJqS-sXSln4GS 1648733430000 "{...}"
对于组织树模块like的场景,我们可以通过zunionzstore命令求多个set的并集来实现。形如:
zunionzstore set1 set2 set2... uset
然后通过ZSCAN 命令进行筛选,这块其实类似于hbase的rowkey原来,我们需要好好的设计redis中的value的构成。需要将筛选条件一并设计进去。比如:read=0&type=1#{...}。那么我们可以通过如下脚本过滤出read=1的数据。
scan uset 0 match "read=1*"
此方案在数据量比较小的场景下应该是没问题的,如果set数量比较多,而且每个set数据量比较大的话,性能应该是无法保证的。比如:每个set里面有百万数据。
我们再回到MySQL上来。更新的场景OLTP数据库都快不起来,只能采用预编译批处理的方式:一批1000,慢慢来更新。我们惊喜的发现:对于我们的查询场景,MySQL非常适合。因为MySQL索引的底层数据结构就是B+树。我们只需要在告警表中,增加告警时间的索引。由于本身索引构建的时候就是顺序构建的,我们的查询场景order by字段只有告警时间,所以整个查询过程非常的快。查询1000万条告警信息,按照告警时间倒序排序取前10条,响应时长在毫秒级。使用mysqlslap对查询SQL进行压测,发现在我们如此脆弱的虚拟机上(8C 16G)上,告警查询TPS也能达到500+,完全能满足我们的业务需求。
至此我们也能总结出比较合适的方案:更新、简单的高并发范围查采用MySQL数据库,OLAP场景大量数据的秒查采用ClickHouse数据库。MySQL中数据通过binlog的方式同步到ClickHouse数据库中。这件事情给我的感触还是比较深的:这个世界永远没有银弹,合适的才是最好的。有时候一直存在的东西,也许都是各方权衡的结果,永远没有最优的解,唯有一直的努力!

信息大爆炸的时代下的今天,运维人员每天都要处理成千上万的信息。面对各种运维事件,想获得足够的告警信息,单一的监控系统显然是不够的。越来越多的运维团队同时用着多种监控工具,这些工具每天都会发出成百上千个告警。运维成员每天都面对着冗杂且繁复的告警信息,运维工程师们很难了解,哪些告警信息才是最关键的?哪些告警信息是重复可替代的?哪些告警信息又是可以忽略且清除掉的?于是处理告警通知就成了最头疼的事情,而且把时间都耽误在了处理错综复杂的无效告警上,错失掉真正需要关注的信息。严重的,会直接影响线上业务的使用,致使客户流失。
面对这一切,运维工程师们都想找到一个可以解决告警通知的办法。这不,方案来了!智能告警平台 Cloud Alert(以下简称CA)可快速接入各类告警信息,通过人工智能算法自动去重降噪,减少冗余告警。并配合分派策略、排班机制,以多种方式通知告警到相关人员,帮助企业用户形成 标准的告警事件处理流程,让业务运行更可靠。

通知前,先压缩
研究调查表明,85% 的运维团队都曾错失过极为严重的告警事件,并且99% 的人都承认遗漏掉的告警,对他们的业务发展有着潜在且巨大的风险。丢失掉的报警往往会引发一系列的问题,处理不掉就会很容易造成停工懈怠,而此类问题会急速地降低用户体验,大幅度缩减企业收益,甚至导致企业面对更大的商业威胁。
其实告警通知的第一步,就是在告警产生时,就对告警信息做好分类和分工。告警监控的重要性是不言而喻的,找到痛点并有序的进行下一步工作,才能够更好的改善告警响应机制。这时候,你需要的是一栈式地为告警事件的响应做出统一且合理的安排和规划,最大限度的将告警压缩,合并信息的根源,避免低端无效的告警通知信息。

灵活排班,多渠道通知必达
通过智能化的手段进行了告警收敛,可以很快的确定出现告警的关键问题所在,而下一步要做的就是衣最快的速度,找到最快能解决该问题的人员。所以就要采用自动化的升级功能,能够把最佳的方案放到最合适的环境中去运用,并逐层分级指派给特定的人选。不断的调整优化时间管理流程,以确保能够为运维团队发挥最大的益处。
Cloud Alert 通过完善的分派和升级策略,可以实现 7*24h 全面覆盖各种IT风险,保障业务不间断运营,并基于告警内容的分派,确保业务问题能够实时地发送给正确的人员和团队。 同时,可搭配平台自有的多渠道通知模块,针对不同的告警,进行多渠道的通知,Cloud Alert支持电话、短信、邮件、微信、APP等一对一通知,也支持钉钉、倍恰、简聊、slack、udesk、企业微信、飞书等第三方协作通知方式。通过这一系列的灵活分派策略和组织分工,可以快速地帮助企业落地告警管理流程。
· 对于一对一的通知方式,用户可以根据告警状态、告警级别、通知时间、延迟通知选择、通知方式等多种类别,将不同的告警进行区分通知;
例如,用户可以指定严重级别的告警在全部的时间立刻电话通知到相关人员;指定警告级别的告警在工作时间立刻邮件和微信通知,非工作时间立刻短信通知;指定提醒级别的告警在任何时间延迟30分钟后短信通知;

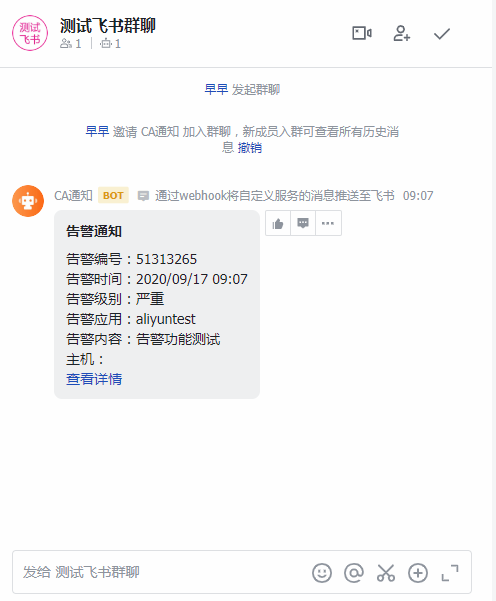
· 对于第三方协作通知的方式来说,协作通知可以将指定的告警通过第三方平台,进行通知,使得平台中的人可以一起处理告警通知。针对钉钉、企业微信、飞书,这三个平台,用户可以选择在平台中对告警进行认领或者关闭告警;钉钉和企业微信还支持指定告警通知@相关人员,这样在告警繁多的时候,就能够更加准确的通知到相关人员进行处理。
钉钉和企业微信通知:


飞书通知:
上文就是小编问大家整理的告警查询及处理的优化之路,告警处理流程包括。
国内(北京、上海、广州、深圳、成都、重庆、杭州、西安、武汉、苏州、郑州、南京、天津、长沙、东莞、宁波、佛山、合肥、青岛)睿象云智能运维平台软件分析、比较及推荐。


发表评论
暂时没有评论,来抢沙发吧~